画像認識AIの仕組みとAI開発自動化技術

画像認識AIは、自動運転や医療、セキュリティなど多くの分野で活用が進んでいます。しかしながら、AI開発現場では、大量の教師データを確保するための苦労や、ディープニューラルネットワーク(DNN)の最適化に要する膨大なコストなど、多くの課題を抱えています。ここでは、画像認識AIの開発における課題や、それを解決するための開発自動化技術について解説します。
画像認識AIとは
画像認識AIとは人物や文字、図形など、画像をもとに識別するAIです。例えばスマートフォンで撮影した画像を分析し、「これは自動車」「これは歩行者」といった識別を行わせることが可能です。自動運転や防犯カメラ、医療診断など、幅広い分野で活用が進んでいます。
| 種類 | 概要 | 活用シーン |
|---|---|---|
物体認識 |
形状などの特徴から物体を識別する | 自動運転 防犯カメラ 医療診断 |
顔認識 |
顔の特徴から個人を識別する | スマートフォンのロック解除 キャッシュレス決済 出入国管理 |
文字認識 |
文字を識別する | 郵便物の自動仕分け ナンバープレート読み取り 文字翻訳 |
異常検知 |
異常な特徴や動作を検出する | 不良品の検出 食品異物の検出 機械の異常動作検出 |
キャプション生成 |
画像の状況を説明する文章を生成する | 動画キャプション自動生成 動画チャプター自動生成 |
人が設計する従来型の画像認識
画像認識において、学習処理や識別処理に用いられる情報を「特徴量」と呼びます。例えば、赤いリンゴや、黄色く曲がった形状のバナナを識別する場合に「どの程度赤いか」「どの程度曲がっているか」を数字で表したものが特徴量です。従来型の画像認識では、特徴量として何を用いるかの選定や、特徴量を抽出するためのプログラミングは人間の手によって行われていました。
図形識別を例に説明します。物体形状の識別にしばしば用いられるものに「エッジ方向」と呼ばれる特徴量があります。エッジとは、急激な明るさの変化を伴った画像領域を指し、その明るさの変化方向をエッジ方向と呼びます。
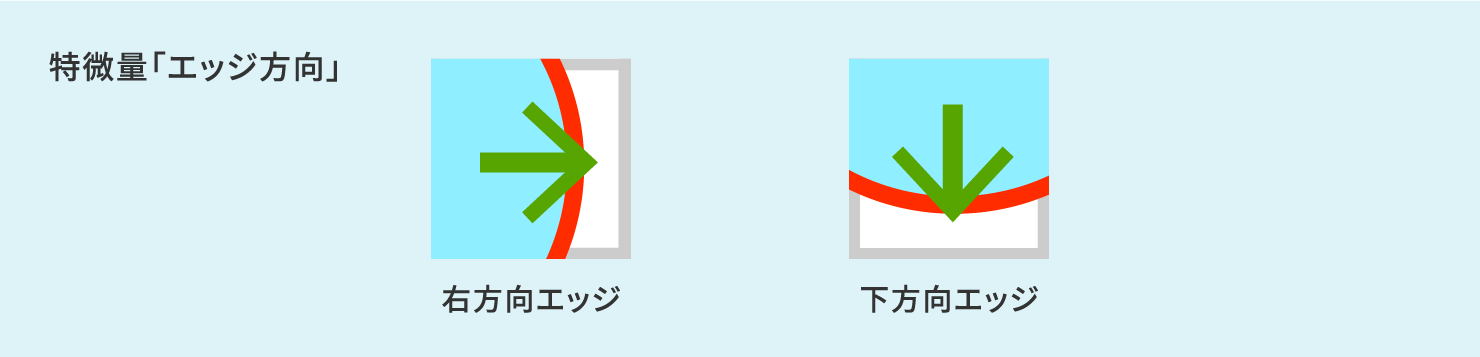
下記のように、丸と三角、それぞれの図形ではエッジ方向の分布が異なることから、その分布をプログラムでカウントすることで両者を識別することが可能となります。
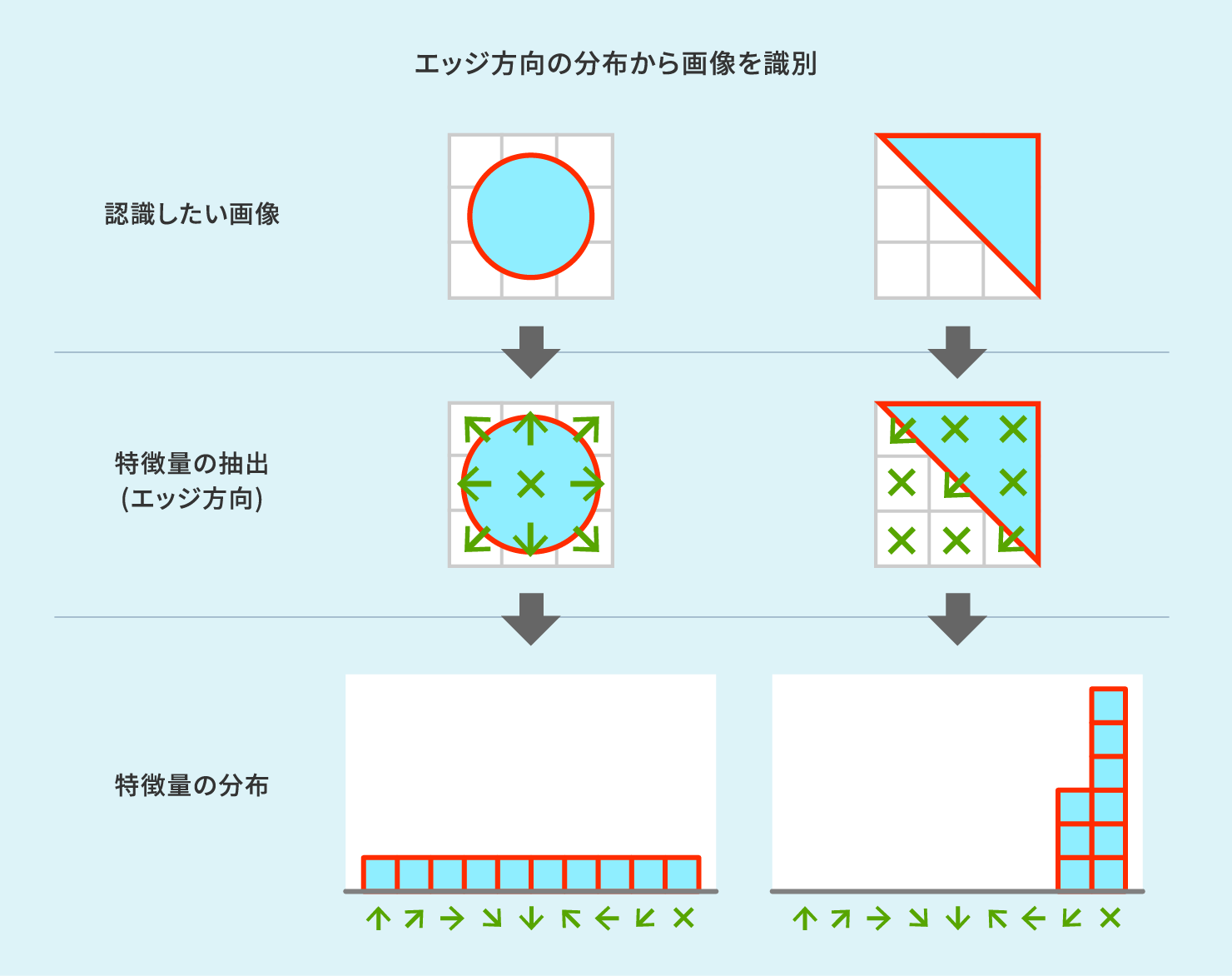
従来型の特徴量ベースの画像認識では、このように人間が選定した特徴量を用いて画像認識を実現していました。
人が設計しないDNN
これに対してディープニューラルネットワーク(DNN)では、どのような特徴量を抽出するかを人間が選定することは無く、学習の過程で決定されます。DNNの中でも画像認識AIとして有名なコンボリューショナルニューラルネットワーク(CNN)を例に説明します。
CNNはコンボリューション層と呼ばれる特徴量を抽出する部分と、全結合層と呼ばれる識別を担う部分で構成されます。
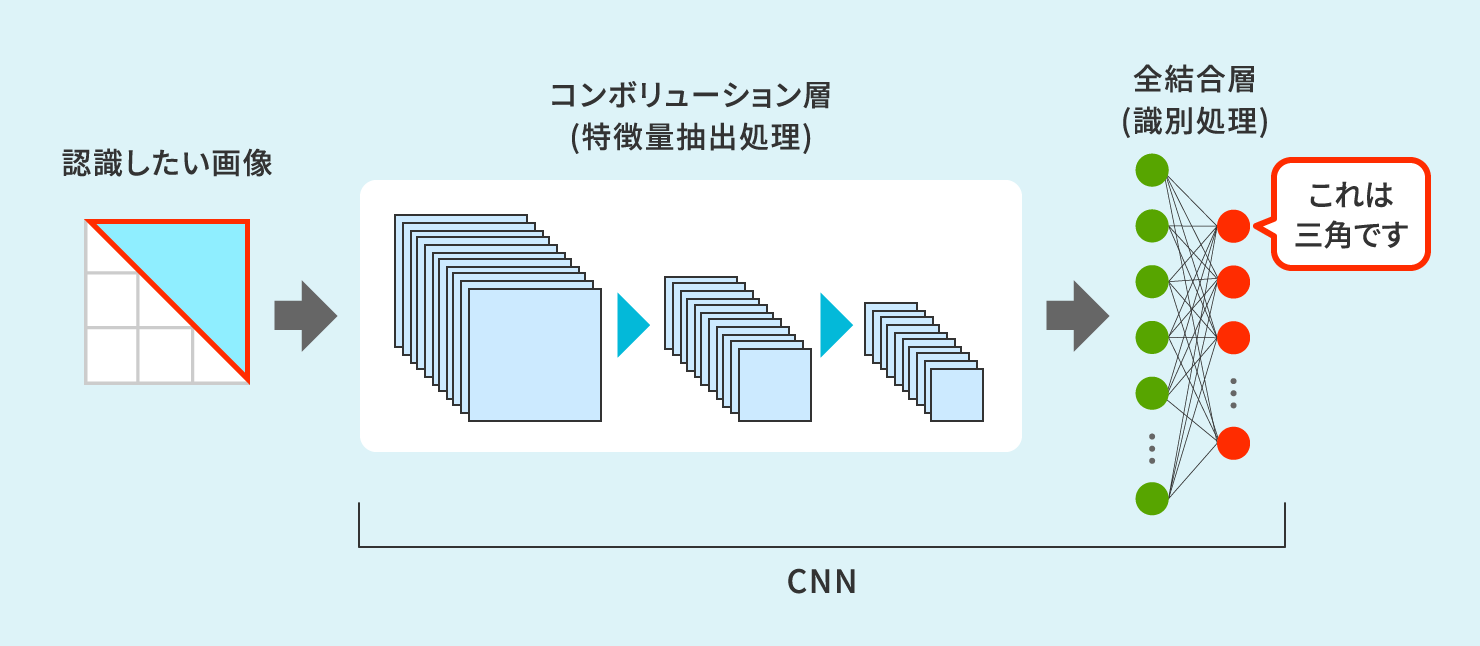
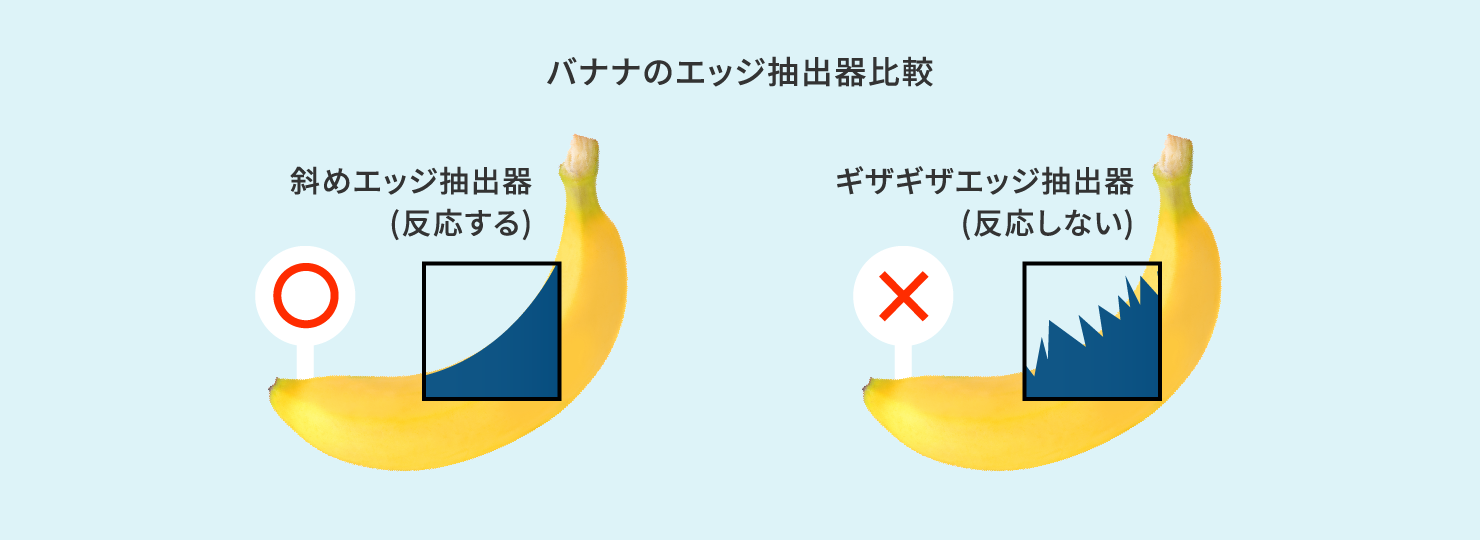
はじめに、コンボリューション層には膨大な種類の特徴量抽出器(コンボリューションフィルタ)が用意されます。それらは先ほどのエッジ方向特徴量抽出器であったり、黄色や紫色などの色特徴量抽出器であったりさまざまです。ここで、バナナを識別するためのコンボリューション層を構築してみます。バナナが描かれた教師データ画像をそれらの特徴量抽出器にかけてみると、そのうちの「斜めエッジ抽出器」は反応し、「ギザギザエッジ抽出器」は反応しません。なぜならバナナ画像にはギザギザの領域が存在しないからです。反応しない不要な抽出器を除去していくと「バナナを識別するための特徴量抽出器」で構成されたコンボリューション層が形成されます。
ごらんの通り、コンボリューション層でどのような特徴量を用いるかの選定に、人間は関わっていません。それどころか、CNNが特徴量として何を採用したかもわかりません。人間の役割はコンボリューション層形成に必要な大量のバナナ画像(教師データ)を用意することです。
これは、全結合層でも同様です。全結合層は特定のアルゴリズムで識別処理を行うのではなく、学習によって獲得された「重み」と呼ばれる数値の組み合わせで識別します。この重みの決定も人間による設定ではなく、大量の教師データを読み込ませた結果、「多くの画像で、より正確に識別できる重み」が学習処理により自動で設定されます。
一枚一枚画像を投入して少しずつ重みを調整・変更すると、最終的には正解を導き出せるようになるイメージです。
両者の違い(メリット/デメリット)
設計に人間が大きく関与する従来型の画像認識と、大半が自動で構築されるDNN、両者は仕組みや学習方法に大きな違いがあります。それらの違いは機能や性能にどのような影響を及ぼすのでしょうか?
DNNの高い識別精度
1~数種類の特徴量で識別処理をしていた従来型の画像認識に対し、膨大な数の特徴量を扱うDNNは、従来型の特徴量ベースの画像認識に比べて圧倒的に高い識別精度を実現しました。
演算量の爆発的な増加
その代償としてDNNは特徴量抽出回数が増大し、演算量も膨大なものとなりました。そのため、演算リソースや消費電力に制約のある組込み機器では今なお従来型の画像認識手法が幅広く利用されています。
最適化の難しさ
多くのシステムでは、処理高速化やメモリ使用量の削減などいわゆる最適化が行われます。最適化による廉価CPUへの切り替えや、性能向上などが見込めるためです。しかしながら昨今のDNNは大規模化が進み、膨大な数の調整を全て人手で行うことは困難になりつつあります。
学習量の増大
DNNに代表される昨今の画像認識AIは、高い認識精度と引き換えに膨大な数の教師データを必要とするようになりました。当社の例では、小規模なAIの開発案件では五千枚の教師データを投入し、12時間の学習時間で完了できたものが、最近の大規模なAIの開発案件では10万枚を超える教師データを投入し、数ヶ月の学習時間を要することも珍しくありません。
AI開発における自動化技術の重要性
DNNは高い性能と引き換えに、より多くのコストや開発期間を必要とするようになりました。従来であれば、より演算効率の高いアルゴリズムの開発や、より認識精度の高い特徴量の研究などを経て、最適化や識別精度向上を実現することができました。しかしながら、大規模化の進んだ昨今のDNNにおいて、全てを人手で行うことは非現実的になりつつあります。DNNの最適化作業の多くはトライアンドアンドエラーを繰り返す単純作業でもあります。貴重なAIエンジニアを単純作業に長期間アサインするのは非効率であり、活用可能な自動化技術があれば積極的に採用するべきです。それは、教師データ作成においても同様で、膨大な数の教師データの作成コストは時にAI開発コストを超えることすらあります。また、教師データ作成日数の長期化により、ライバル企業に先を越されてしまう事態も起こりえます。そのような事態を防ぐためにも開発速度向上に有利な自動化技術の採用はとても重要です。
AI開発自動化技術導入による最大のメリット
自動化技術の導入により、多くのメリットが得られます。直接的なものとしては、コスト削減と開発期間圧縮ですが、実はそれらを大きく凌駕するメリットが自動化技術にはあります。それは「開発サイクル向上によるビジネス成功率アップ」です。
人手で設計・プログラムされるシステムと異なり、AIは必ずしも開発者の意図通りに動作するとは限りません。プログラムが意図せぬ挙動をした場合は、設計見直しやバグ修正で対応しますが、AIの場合は設計やアルゴリズムで実現しているわけではないことから、同じ対応では解決できません。意図せぬ挙動を見つけた場合、AIのチューニングや教師データの変更を通じて改善状況を確認していくトライアンドエラーを何度も繰り返します。この繰り返しサイクルはMLOps(Machine Learning Operations)と呼ばれ、AI開発では一般的な手法となっています。
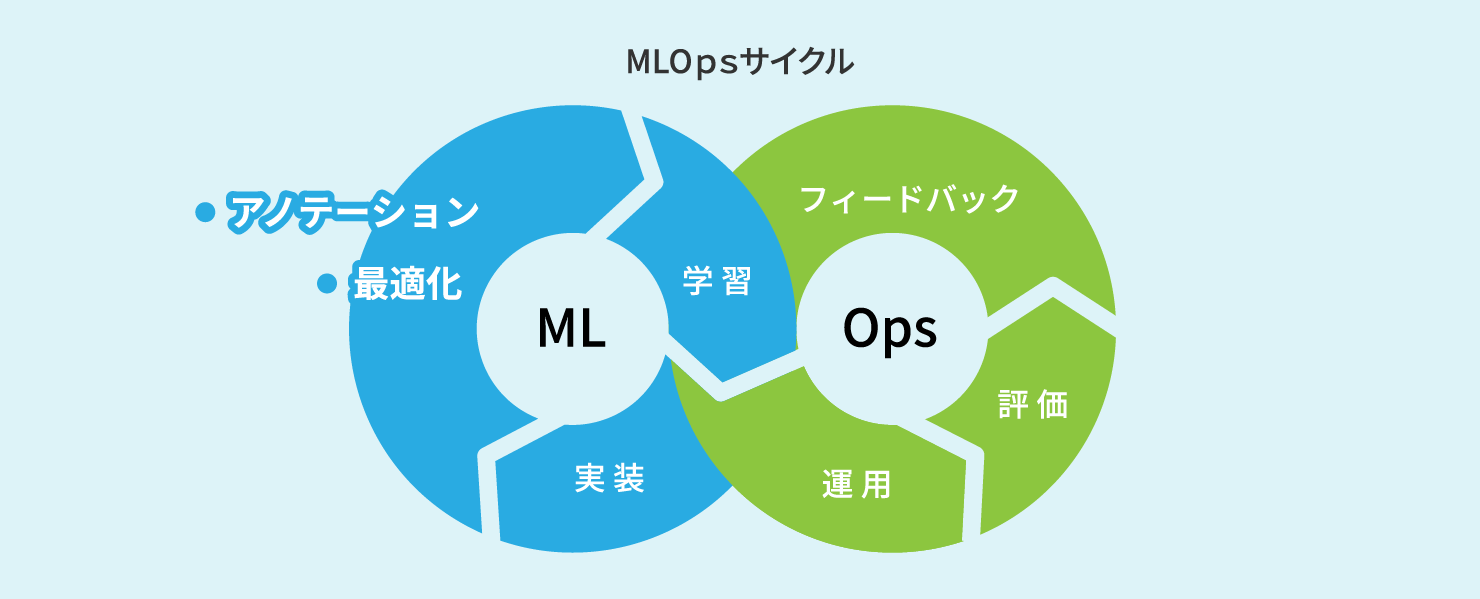
AI開発においては、このMLOpsサイクルをより多く回すことは非常に重要で、回転数が多ければ多いほど、市場が求めるAIに機能・性能で理想に近づくチャンスが多くなり、最終的なビジネス成功の確率が高まります。このため、AI開発者の皆様には是非とも自動化技術の導入をお勧めしたいと考えます。
東芝情報システムのAI開発自動化技術
画像認識AIは進化と共にシステム規模が拡大し、最適化や教師データ確保への課題も増大しました。当社は他社に先駆けてDNN高速化サービスと自動アノテーションサービスを提供し、AI開発の高度化に貢献してまいりました。今後もAIは大きく進化していくことは間違いないため、引き続き当社も新たな自動化技術の開発を進めてまいります。
関連情報・サービス
-
組込み向け画像認識の処理時間を大幅に短縮 「DNN高速化サービス」
大規模・高精度になっていくDNNモデルの最適化には、認識精度と処理性能がトレードオフの関係にあります。また、最適化には修正・計測・評価を繰り返すため、コストと期間が必要となります。これらの課題を独自の...
-
アノテーション自動化ツールで高精度な教師データを短期間で大量に自動作成
アノテーション自動化ツールは、コストを削減しながら短期間で高精細な教師データを大量に自動作成します。AI開発における期間短縮・効率化に貢献します。